(接上文)
Q2: What data do you need?
这一步包括 feature definition 和 table schema design. 在实际工作中, 很多情况下我们做数据分析或者建模工作所需要的数据并不是现成的. 我们需要自己定义 table schema 甚至自己在产品中添加 log 来收集数据. 这也是实际工作与 Kaggle competitions 或 course projects 的区别之一.
Table schema design 并不难, 我们需要注意结合数据内容的「安全级别」和「数据量」把信息分类存放,比如
- User profile table
- Product feature table
- User-item activities table

- Ads table
对于 Data Scientist 和 ML engineer 岗位的 case study, 这一步也会涉及到 label definition 的讨论. 举一个简单的例子: 对于某一个用户, 如果我们 optimize for ads click 的话, 我们可以把 candidate products 中用户点击过的广告商品定义为 positive label (1). 那么如何定义 negative label (0)? 是不是要把其他全部商品定义为 negative label? 一个值得讨论的处理方法是: 结合 impression data, 只把 viewed but not clicked 商品定义为negative label.
Q3: How to design a rule-based recommendation system?
在 case study 面试中, 我们不一定非要给出 model-based solution. 结合具体的应用场景和产品要求, rule-based solution 在很多情况下效果并不差, 比如在计算实时性要求较高, 或者推荐系统中用户行为数据较少 (比如 cold-start problem) 的情况下, 我们更倾向于先给出 non personalized solution 作为 baseline.
在这一步中, 我们可以把商品推荐方法设定成: Always recommend the top 5 popular handbags among female users in the age range between 20 and 30 in United States. 很显然, 要想得到这个信息, 我们可以利用在 Q2 中设计的 tables 做 SQL query. 这也就是 case study 面试中比较常见的SQL考法: 面试者根据优化目标, 自己设计 table, 自己设计问题, 然后自己写出 query 来解决它.
Q4: How to design a personalized recommendation system?
以 rule-based 方法为 baseline, 我们可以进一步利用 supervised learning model 来优化推荐系统的 content relevance. 在这里需要注意的是, 不要直接进入 model loss function 细节的讨论, 而是最好先把整个 machine learning workflow 快速介绍一下, 如下图所示:
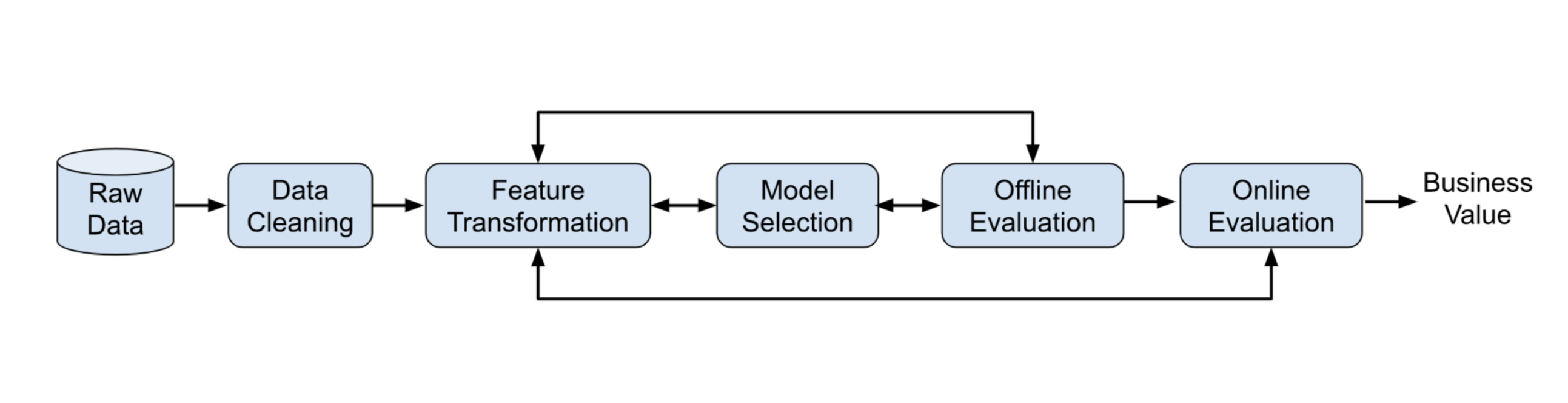
这就是我前面提到的解决问题框架之一, 看上去确实非常简单, 但里面每一个环节都可以进一步深挖. 比如:
Q4.1: How to deal with categorical features at feature transformation stage?
这里涉及到 feature encoding 的方法, 比如 one-hot encoding, label encoding, target encoding等. 如果选择用 one-hot encoding 这种 sparse representation 方法的话, 后续也要考虑模型对 sparse feature 的处理能力, 很多情况下我们需要做降维处理.
除了 Principal Component Analysis (PCA) 方法外, Neural Network Embedding 是很好用的降维方法. 而如果选用 embedding 方法的话, 又涉及到这个 Neural Network 训练使用的 label 与原推荐系统模型使用的 label 是否一致的问题.
Q4.2: When and why do we need to do feature normalization?
Feature transformation 这一步涉及到很多内容, 前面的 Q4.1 算是 feature representation 的处理, 其他的操作还有 feature normalization, missing value handling 等等.
其中 feature normalization 就是 scale all the numeric feature values, 它可以在机器学习模型参数求解的过程中可以帮助数值优化算法更快收敛到最优解. 但这个操作并不是必须的, 需要考虑 feature 的物理意义.
由于面试时间的限制, 肯定不可能对每一个环节都做面面俱到的讨论. 因此在这一步面试官会选择1-2个方向做deep dive.
(未完待续 ... )
